Estimators, Part 1
University of Toronto
July 17, 2023
Terminology
We observe data: \(x_1,...,x_n\)
- Summary statistics can be calculated from data e.g. sample mean, sample variance
We don’t observe random variables: \(X_1,...,X_n\)
- Likewise, we can’t observe functions of random variables e.g. expectation value, variances
We want to use the observed data to learn about the unobservable probability distributions.
Estimate → Estimator
A estimate is a value \(t\) that only depends on the dataset \(x_1, ..., x_n\), that is, \(t\) is a function of the dataset only:
\[ t =h(x_1, ...,x_n) \]
An estimator is a random variable \(T\), defined as:
\[ T=h(X_1, ...,X_n) \]
such that the estimate \(t\) is a realization of \(T\).
Often, we want to estimate a model parameter, e.g. \(\theta\). In this case, the notation commonly used to denote an estimator is \(\widehat{\theta}\)
Sampling distribution
For an estimator \(T=h(X_1, ...,X_n)\) based on a random sample \(X_1, ...,X_n\), the sampling distribution is the probability distribution of \(T\).
Example 1 Let \(X_1,...,X_n\overset{iid}{\sim}F_{\theta}\). Consider the estimator \(\widehat{\theta}=X_3\).
Solution. \(X_3 \sim F_{\theta} \implies \widehat{\theta} \sim F_{\theta}\)
Sampling distribution
Example 2 Let \(X_1,...,X_n\overset{iid}{\sim}Bernoulli(\theta)\). Consider the estimator \(\widehat{\theta}=\bar{X}\).
Solution. Notice that each \(X_i\) in the random sample has binary possible outcomes, that is, \(0\) or \(1\) \(\implies\) \(\sum_{i=1}^n X_i\) is a count of the number of successes in \(n\) Bernoulli trials.
Recognize this as a binomial distribution \(\implies\) \(\sum_{i=1}^n X_i \sim \text{Bin}(n, p)\)
Since \(P\left(\sum_{i=1}^n X_i = k\right) = P\left( \bar{X} = \frac{k}{n}\right)\), then \(\widehat{\theta} \sim Binomial(n, p)\).
Evaluating Estimators
Part 1
- Bias
- Consistency
Part 2
- Efficiency
- Mean Squared Error
Bias
An estimator for the parameter \(\theta\) is called an unbiased estimator if
\[ \mathbb{E}[\widehat{\theta}]=\theta \]
The bias of \(\widehat{\theta}\) is the difference \(\mathbb{E}[\widehat{\theta}]-\theta\).
Example 3 Given \(X_1, ...,X_n\) iid with \(\mathbb{E}[X_i]=\mu\). Are the following estimators for \(\mu\) unbiased?
Sample mean \(\bar{X}\) 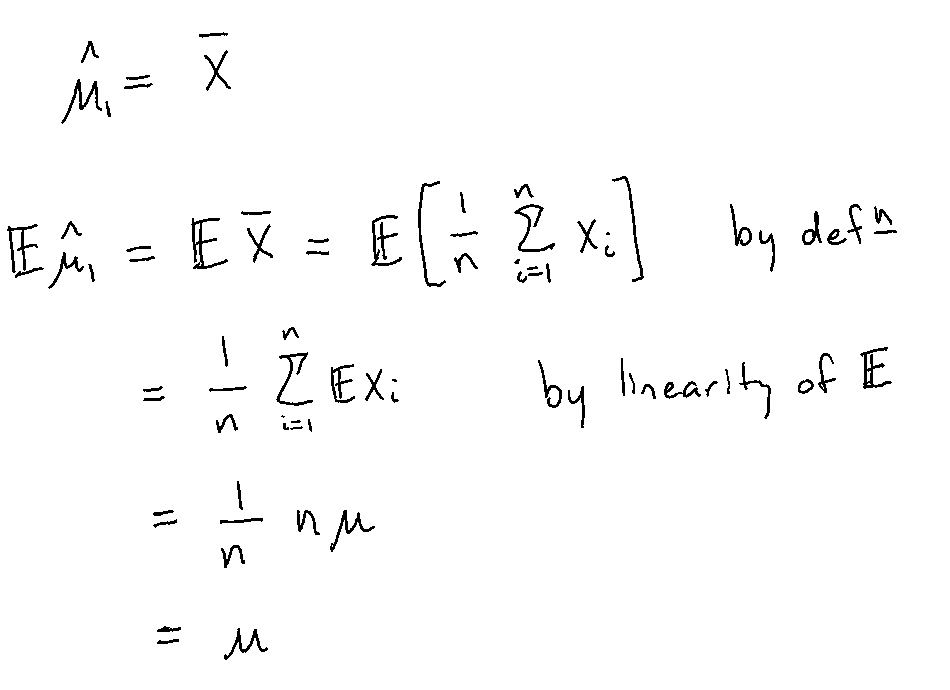
Single observation \(X_1\) 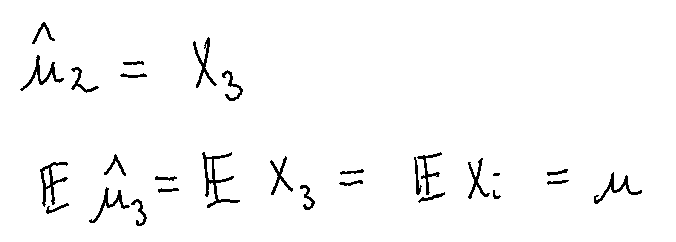
Example 4 Given \(X_1, ...,X_n\) iid with \(\mathbb{E}[X_i]=\mu\) and \(\text{Var}(X_i)=\sigma^2\). Is \(\widetilde{s}_n^2=\frac{1}{n} \sum_{i=1}^{n}( X_i − \mu )^2\) an unbiased estimator for \(\sigma^2\)?
Assume \(\mu\) is known.
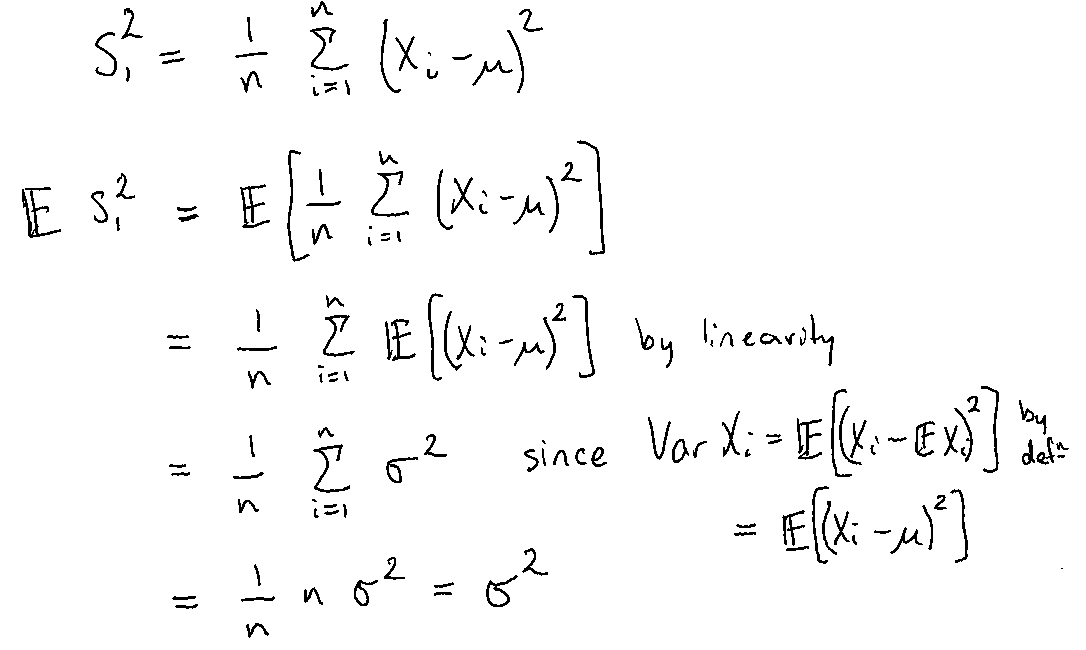
Assume \(\mu\) is not known.
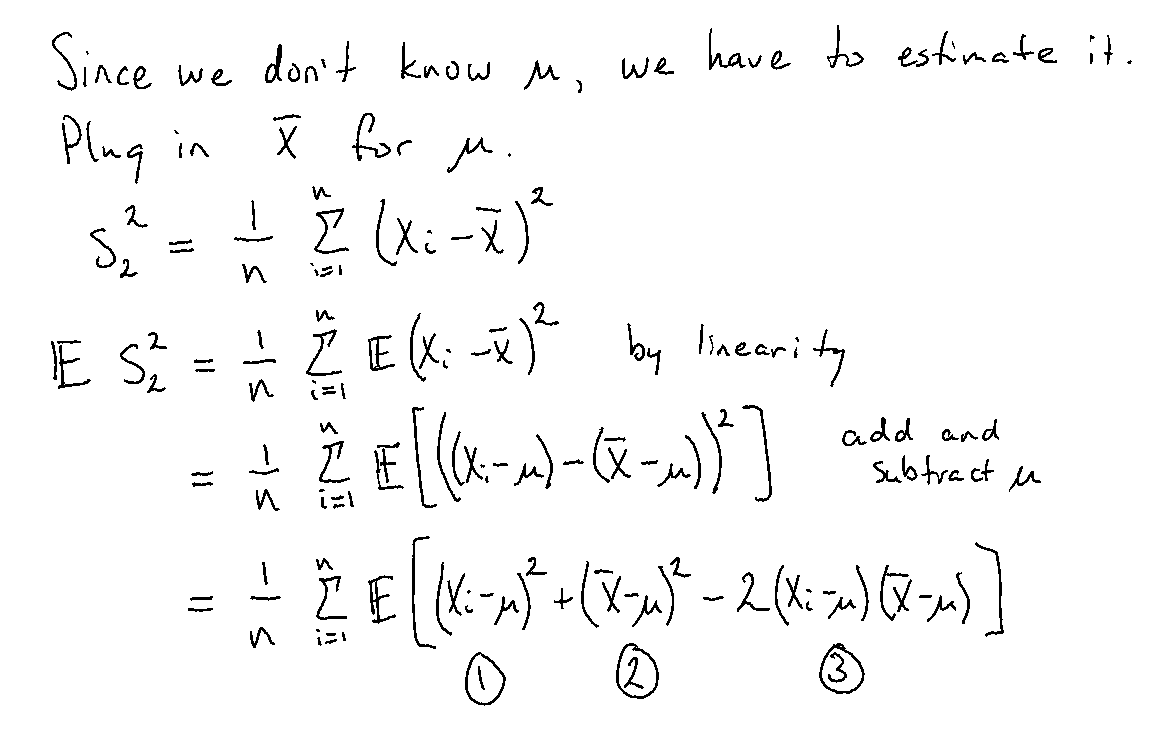
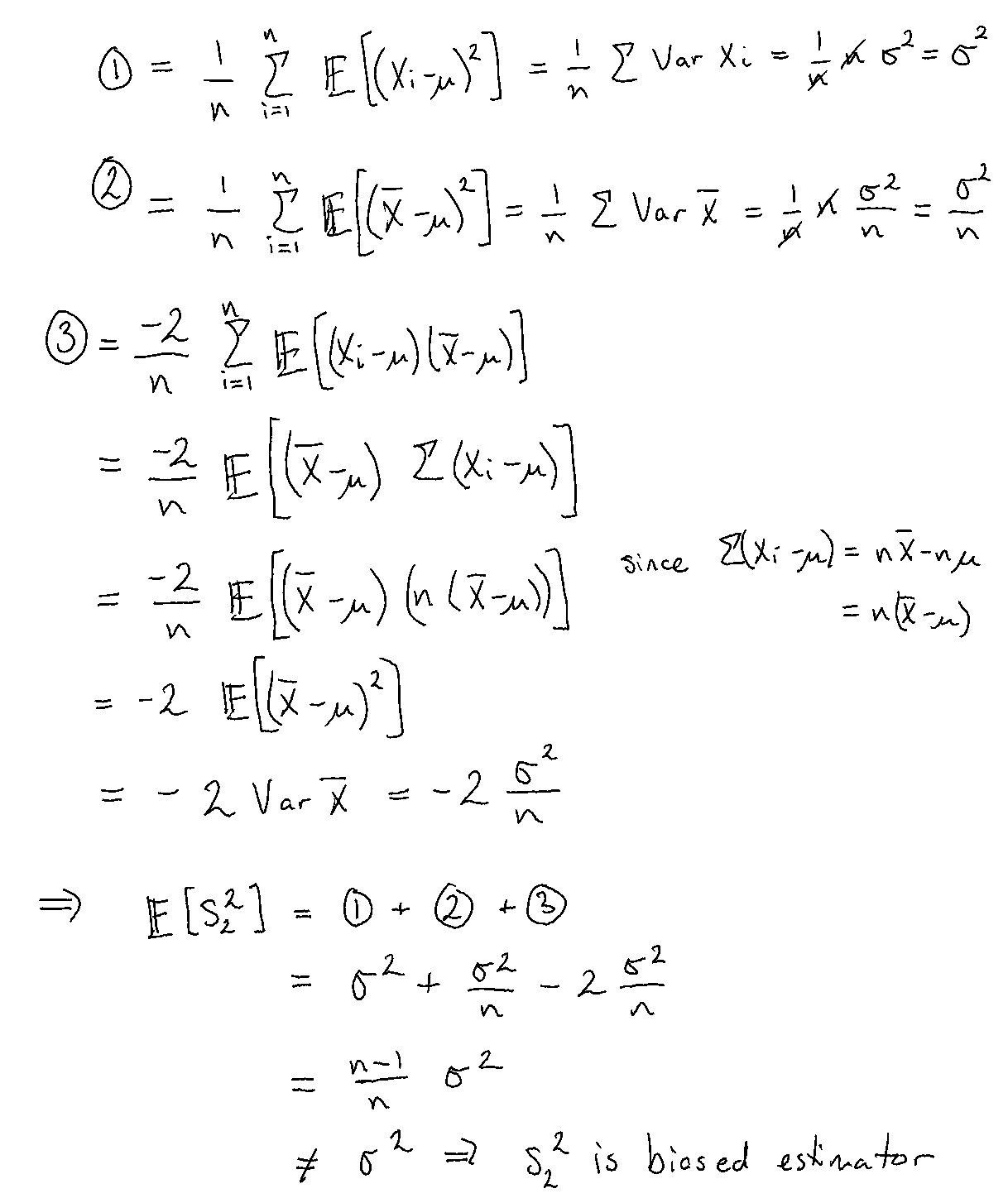
A biased estimator can sometimes be used to construct an unbiased estimator.
A function of an unbiased estimator is not necessarily an unbiased estimator of the function of the parameter.
Consider the square root of an unbiased estimator of the variance as an estimator of \(\sigma\).
Recall: Jensen’s inequality
Let \(X\) be a random variable and \(g\) be a convex function. Then \[ \mathbb{E}[g(X)] \geq g(\mathbb{E}[X]) \]
Example 5 Given \(X_1, ...,X_n \overset{iid}{\sim} \text{U}[0,\theta]\). Find an unbiased estimator for \(\theta\).
For \(X_i \sim \text{U}[0,\theta]\),
\[ f(x|\theta)= \begin{cases} \frac{1}{\theta} &\text{for } 0 \leq x \leq \theta \\ 0 &\text{otherwise } \end{cases} \]
\[ \mathbb{E}[X_i]=\frac{\theta}{2} \]
\[ \text{Var}(X_i)=\frac{\theta^2}{12} \]
Consistency
An estimator \(\widehat{\theta}\) is consistent for a parameter \(\theta\) if \[ \lim_{n\rightarrow \infty} \text{Pr}\left( \lvert \widehat{\theta}-\theta \rvert > \varepsilon \right) = 0 \] for any \(\varepsilon >0\). That is, \(\widehat{\theta} \overset{p}{\rightarrow} \theta\).
Examples
- \(\bar{X}\) is consistent for \(\mu\) (by LLN) and unbiased
- \(\widetilde{s}_n^2=\frac{1}{n}\sum_{i=1}^n (X_i-\mu)^2\) is consistent for \(\sigma^2\) (by LLN, see: Modelling Exercise 1) but biased
- \(X_1\) is unbiased but not consistent