Exploratory Data Analysis
July 6, 2023
Box-and-whisker plot

Histogram
Too small ⇒ too noisy
Too big ⇒ lose features of the data
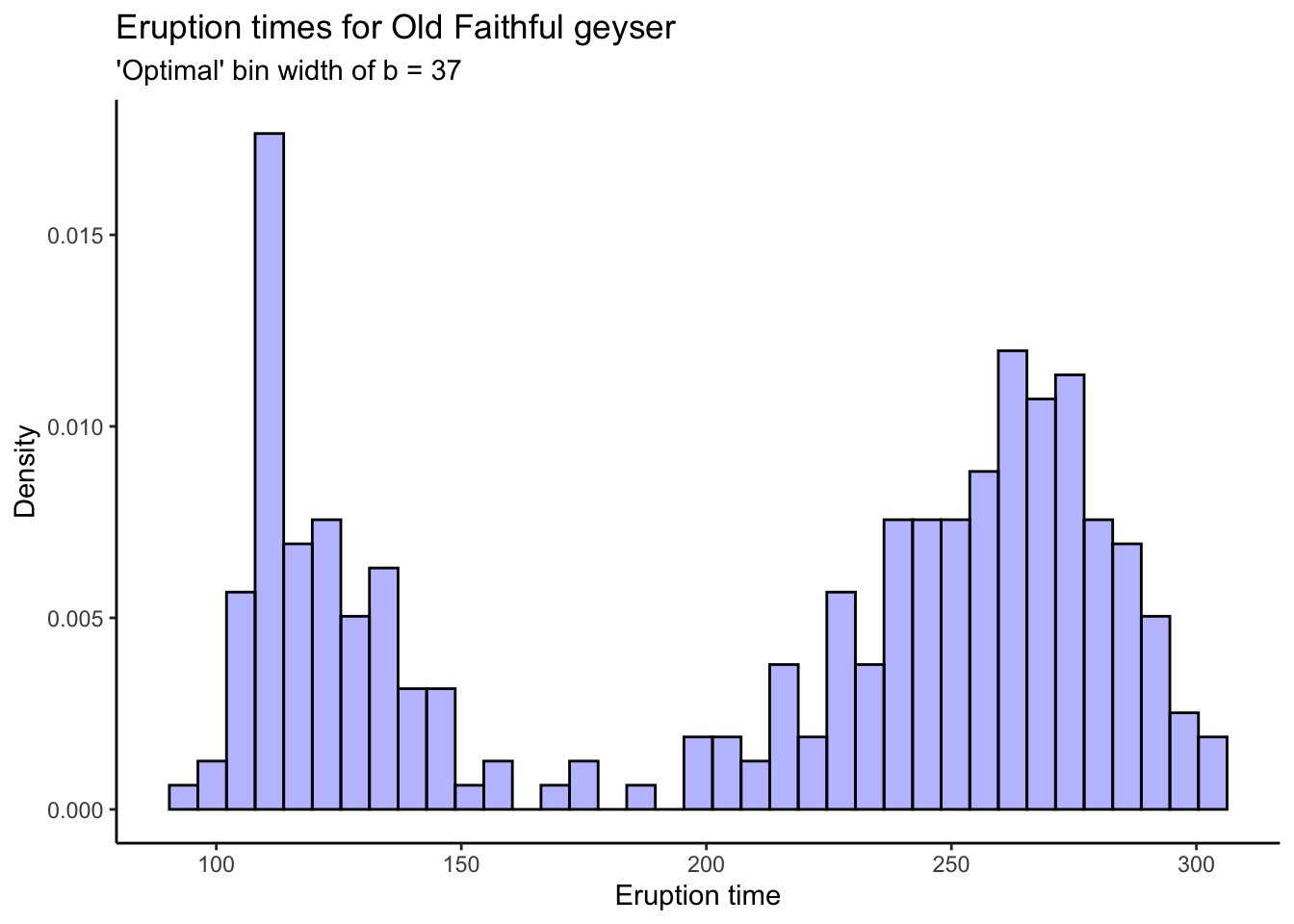
“Optimal” bin width

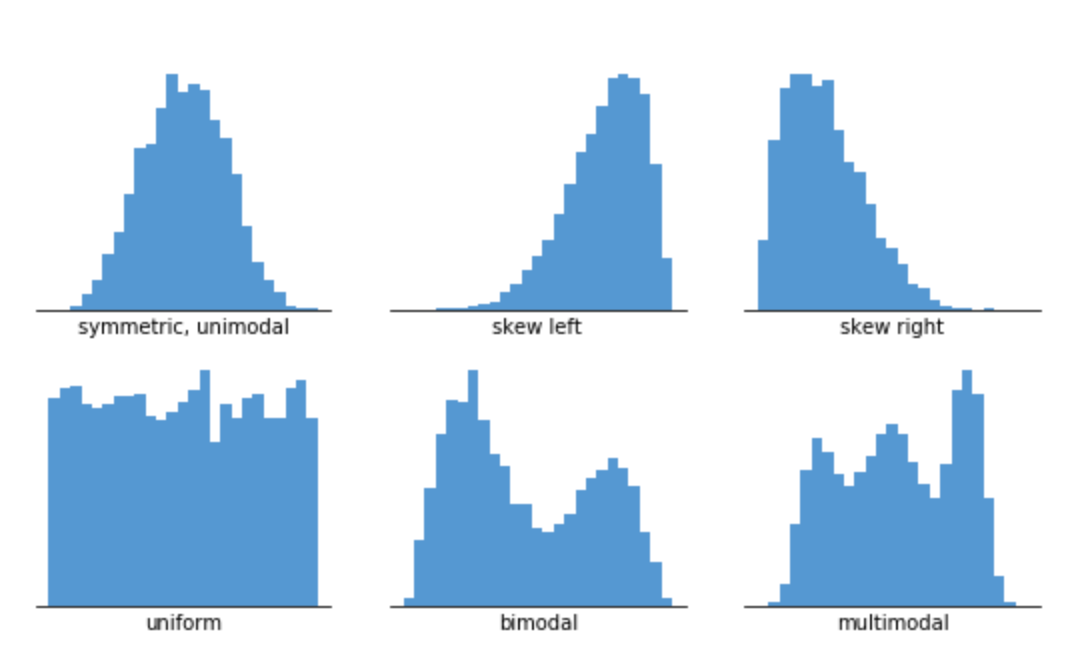
Shapes
Density estimate

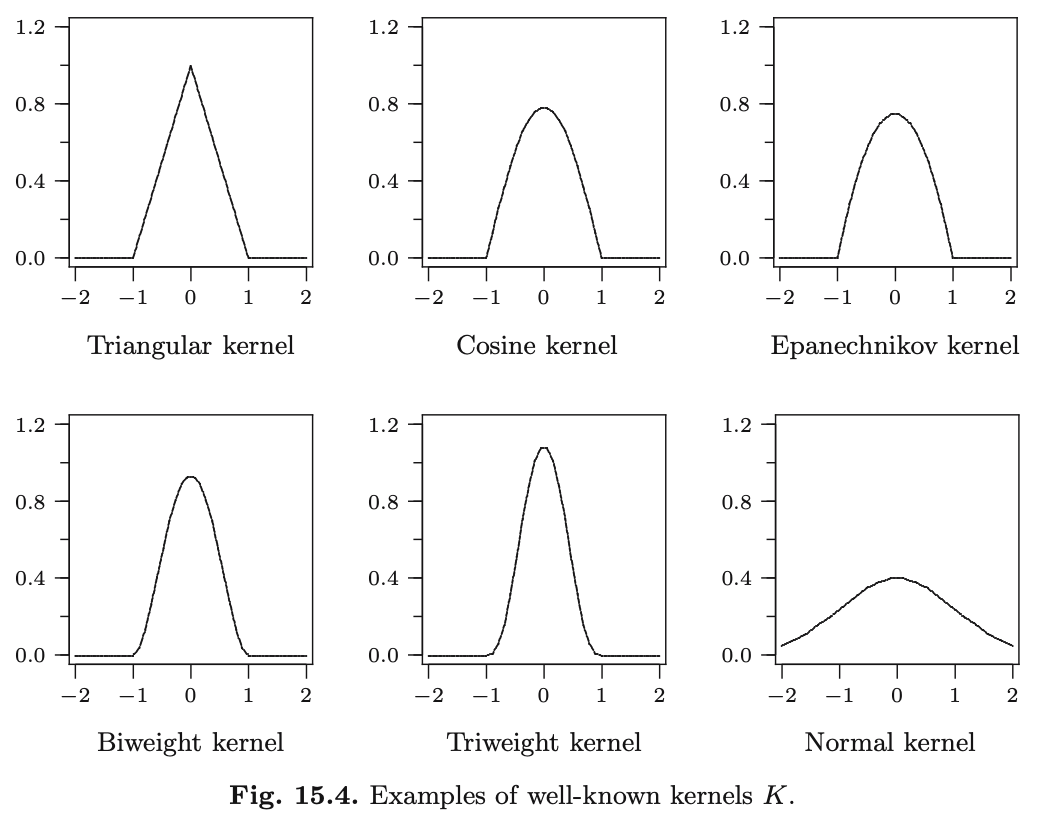
Kernel, \(K(t)\)
Reflects the shape of the sand pile. Choose a shape.
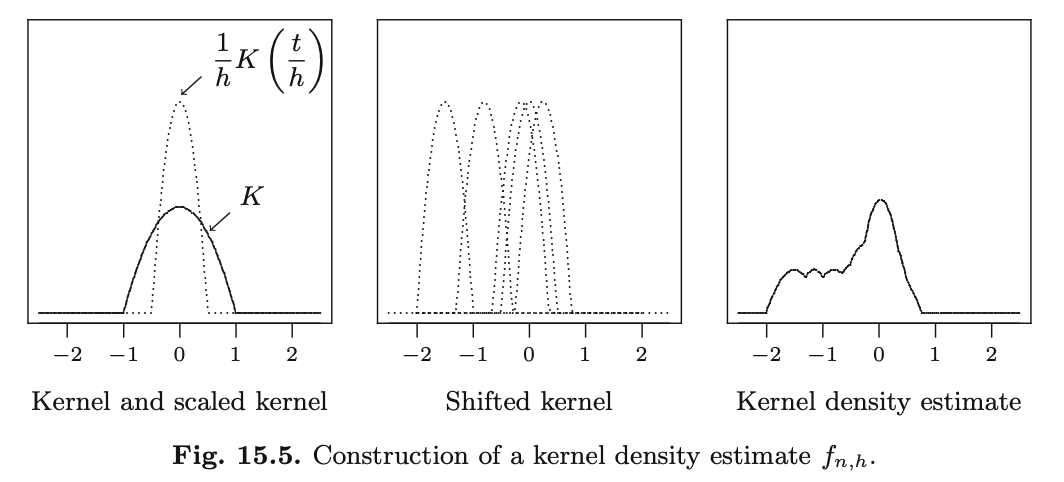
Constructing a KDE
To compute \(f_{n,h}(t)\), shift the scaled kernel to each data point and take the average
\[ f_{n,h}(t)=\frac{1}{n}\left\{ \frac{1}{h} K\left( \frac{t-x_1}{h}\right) + ... + \frac{1}{h} K\left( \frac{t-x_n}{h}\right) \right\} \]
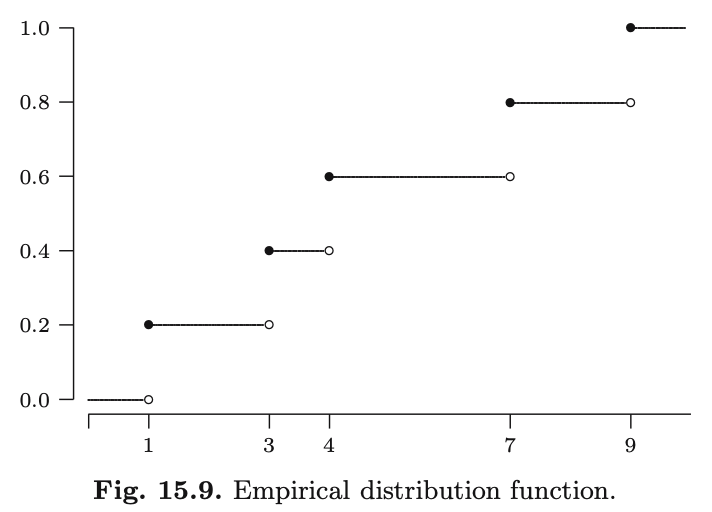
Empirical distribution

Example
Consider the dataset: \(\{4,3,9,1,7\}\)
Scatterplot
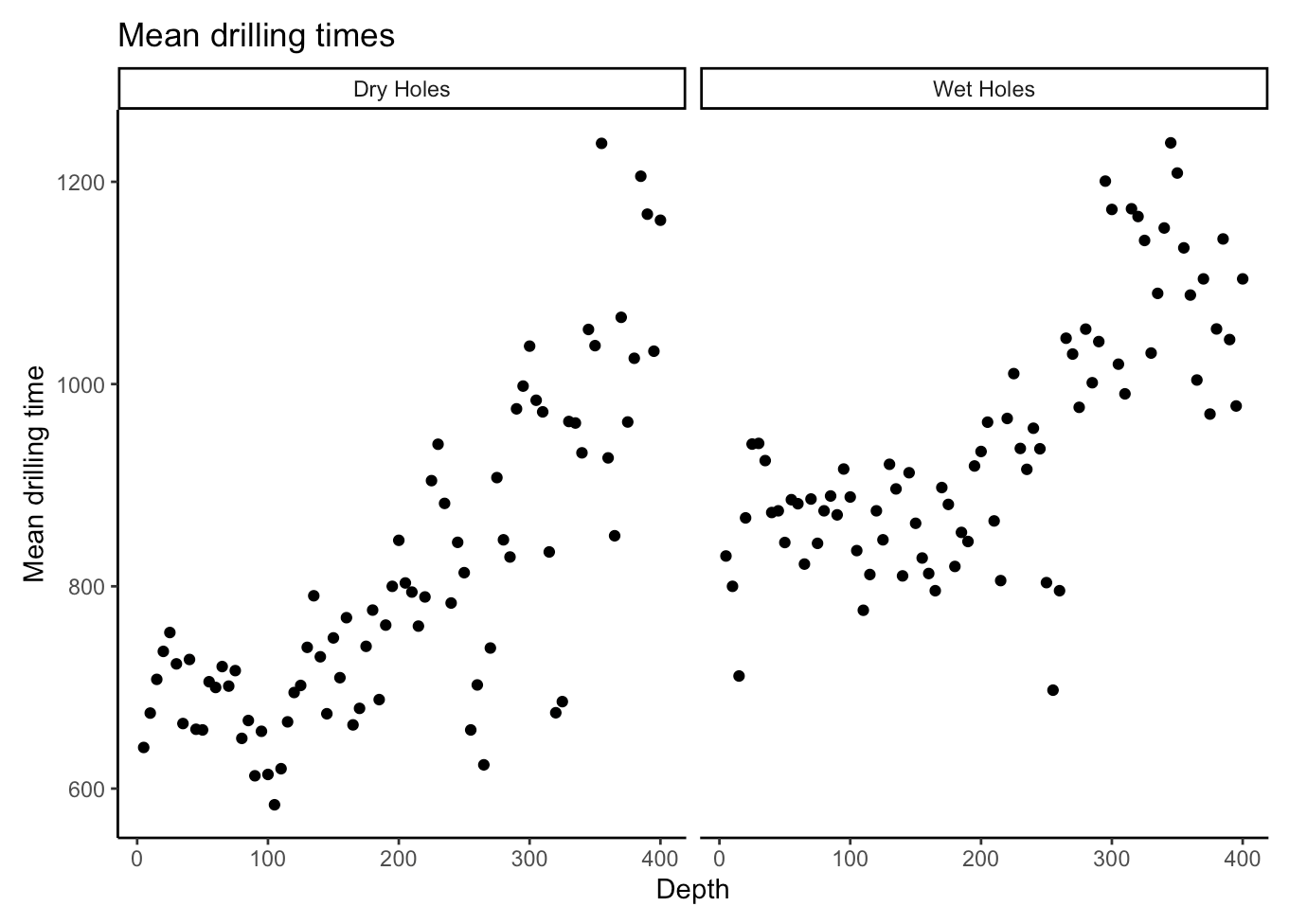
What do scatterplots show?
- Direction
- Shape
- Correlation strength (sometimes)